

Transcription FAQ
Find answers to common transcription questions so you can troubleshoot speaker mapping, transcript formatting, limits, latency, and billing faster.
How do I choose the best transcription provider for my use case?
You can use this sample app to compare transcription quality and output across multiple third-party providers using Recall.ai's async transcription API.
Each transcription provider has unique strengths and drawbacks, so the “best” transcription provider will likely look different depending on your use case.
We recommend picking out a few of the transcription providers and transcribing the exact same meeting multiple times using different providers and configurations. This will allow you to do a direct comparison of the transcript quality for the same conversation. You can do this by recording a conversation, and then calling the Create Async Transcript endpoint to transcribe it. Save the resulting transcript, then run Create Async Transcript again using a different provider or configuration. This should help you understand what works best for your unique use case.
How do I improve/maximize transcription accuracy?
Recall does not have direct control over the quality of the transcript generated by third parties or by the meeting platforms. However, you do still have configuration options available to you to improve the quality of the transcript.
Use a different transcription model
There are two types of transcription model: real-time and asynchronous. Asynchronous transcription is typically higher quality than real-time transcription since the model gets the full context of the conversation when creating the transcription. If you’re okay with waiting until the end of the meeting to receive the transcript, you might want to look into using async transcription. Most of our supported transcription providers have both async and real-time models.
Real-time vs. async in the Recall APITo transcribe a meeting using asynchronous transcription, you need to call the Create Transcript endpoint. If you’re setting up transcription in your Create Bot request, it means you’re using a real-time transcription model instead of an async transcription model.
Change your language configuration
If you don’t know ahead of time which language the conversation will be in, you can set up automatic language detection. This is supported by most of the third-party transcription providers that we integrate with. Automatic language detection is not available when using meeting captions.
There are also cases where people switch back and forth between multiple languages in the same conversation. Some transcription providers also support this in their configuration options.
See Multilingual Transcription for more details.
Add custom configuration based on your use case
It’s worth investigating the different parameters available to you through the different providers. For example, if the transcript is consistently misspelling a company name or a certain proper noun, many transcription providers offer a “custom vocabulary” feature that allows you to specify the correct spelling. You can view all the supported parameters for the different transcription providers in our API Reference pages for Create Bot and Create Transcript. You can also browse the documentation of your chosen transcription provider directly.
Related resources:
Assembly AI | AWS Transcribe | Deepgram | Rev | Speechmatics
How do I improve/maximize diarization accuracy
See Diarization for more details.
How do I match words with calendar participants or email addresses?
If you are using Recall’s calendar integration, you can receive emails in all API responses that contain participant data — you can read more about the feature at Meeting Participant Emails.
Currently, meeting platforms do not expose participant emails directly for privacy reasons. This means there isn’t a built-in way to perfectly match speakers from transcriptions to calendar participants. A common workaround is:
- Use the calendar integration to retrieve participant emails.
- Compare those emails to meeting participant names.
- Apply fuzzy matching between the transcript speaker names and the participant list to associate words in the transcript with the correct email addresses.
Why is the speaker "None" at the start of a transcript?
At the start of a call, someone may be already speaking prior to the bot joining. In this case, there is no active speaker event to tie to the first utterance in the transcript.
In this case, the first utterance will have a speaker of null.
How do I determine transcription hours for a given bot?
The recommended approach here is to check the transcript.data.provider_data_download_url field attached to a recording. This contains the raw data received back from the transcription provider, and should tell you the exact audio duration that was transcribed.
Exampleprovider_data_download_url :
{
"transcript": {
"id": "2c22e1b4-4477-4372-b080-9799a4c7bf5b",
"created_at": "2025-8-11T20:40:45.996425Z",
"status": {...},
"metadata": {...},
"data": {
"download_url": "...",
"provider_data_download_url: "...",
},
"diarization": null,
"provider": {
"assembly_ai_async": {}
}
}
}Will I be charged if media is captured but it contains no speech (e.g., silence)?
Yes. If a recording is captured and processed for transcription but it does not contain audible speech, it can be billed even if there’s no speech (e.g., 20 minutes of silence). The key difference is no media captured vs media captured (even silent).
Fetching custom fields from your transcription provider
If you want to extract a specific field from your transcription provider that is not exposed through the Recall API, then you can download the raw provider data from the transcript artifact:
{
"id": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"data": {
"provider_data_download_url": "..."
}
}
Then download the data from data.provider_data_download_url extract the specific field you need. See the response format here.
How do I get the transcript formatted by sentences?
Recall.ai provides transcripts with word-level timestamps when using Recall.ai Transcription or a Third-Party Transcription. You can then convert this to a user-friendly transcript like a dialogue transcript.
You can fetch the transcript on the recording via the recording.media_shortcuts.transcript.data.download_url. You can then pass the transcript JSON to the following function to get the dialogue/caption transcript:
function parseTranscript(transcript) {
if (!Array.isArray(transcript)) return [];
// coalesce adjacent entries by same participant (mutates 'words' of the kept entry)
const keepers = [];
for (const entry of transcript) {
const participant = entry?.participant;
const words = Array.isArray(entry?.words) ? entry.words : [];
if (!participant?.name || words.length === 0) continue; // skip invalid rows
const key = participant.id ?? participant.name;
const last = keepers[keepers.length - 1];
const lastKey = last && (last.participant.id ?? last.participant.name);
if (last && key === lastKey) {
// Append words to previous entry (keeps all other top-level properties intact).
last.words.push(...words);
} else {
// Keep original object to avoid dropping unknown properties.
keepers.push(entry);
}
}
// Map merged entries to paragraphs with timestamps + duration
return keepers
.map(({ participant, words }) => {
const paragraph = words.map(w => w.text).join(" ").trim();
if (!paragraph) return null;
// First word with a start; last word with an end (words assumed chronological).
const first = words.find(w => w?.start_timestamp);
const last = [...words].reverse().find(w => w?.end_timestamp);
const startRel = first?.start_timestamp?.relative ?? null;
const startAbs = first?.start_timestamp?.absolute ?? null;
const endRel = last?.end_timestamp?.relative ?? null;
const endAbs = last?.end_timestamp?.absolute ?? null;
// Duration: prefer relative seconds; else compute from ISO absolute timestamps.
const duration_seconds =
startRel != null && endRel != null
? endRel - startRel
: (startAbs && endAbs ? (Date.parse(endAbs) - Date.parse(startAbs)) / 1000 : null);
return {
speaker: participant.name,
paragraph,
start_timestamp: { relative: startRel, absolute: startAbs },
end_timestamp: { relative: endRel, absolute: endAbs },
duration_seconds,
};
})
.filter(Boolean);
}
This will return something like the following result:
[
{
"speaker": "Gerry Saporito",
"paragraph": "Hey Jake, how's it going?",
"start_timestamp": {
"relative": 187.37506,
"absolute": "2025-10-14T14:38:09.845Z"
},
"end_timestamp": {
"relative": 190.88506,
"absolute": "2025-10-14T14:38:13.355Z"
},
"duration_seconds": 3.5100000000000193
},
{
"speaker": "Jake Miyazaki",
"paragraph": "Hey Gerry, doing well? Have you tried Recall.ai transcription yet? It works very well",
"start_timestamp": {
"relative": 250.60507,
"absolute": "2025-10-14T14:39:13.075Z"
},
"end_timestamp": {
"relative": 275.91504,
"absolute": "2025-10-14T14:39:38.385Z"
},
"duration_seconds": 25.309969999999964
},
...
]Who is participant 2147483647?
When using output audio with "include_bot_in_recording": {"audio": true} and perfect diarization the bot will transcribe the audio that it's outputting into the meeting. In this situation, the audio will be assigned to the speaker_id 2147483647 which is 2^31 - 1
Can I bring my own recordings (audio/video files) to transcribe?
You can't upload your own recordings (e.g. .mp3, .mp4, .wav) to transcribe at this time.
Instead, you can try transcribing the audio using a third party transcription provider's integration
How can I download the transcript from the dashboard?
You can do this in the dashboard under the transcript component by clicking the 3 dots > Copy > Copy Plaintext
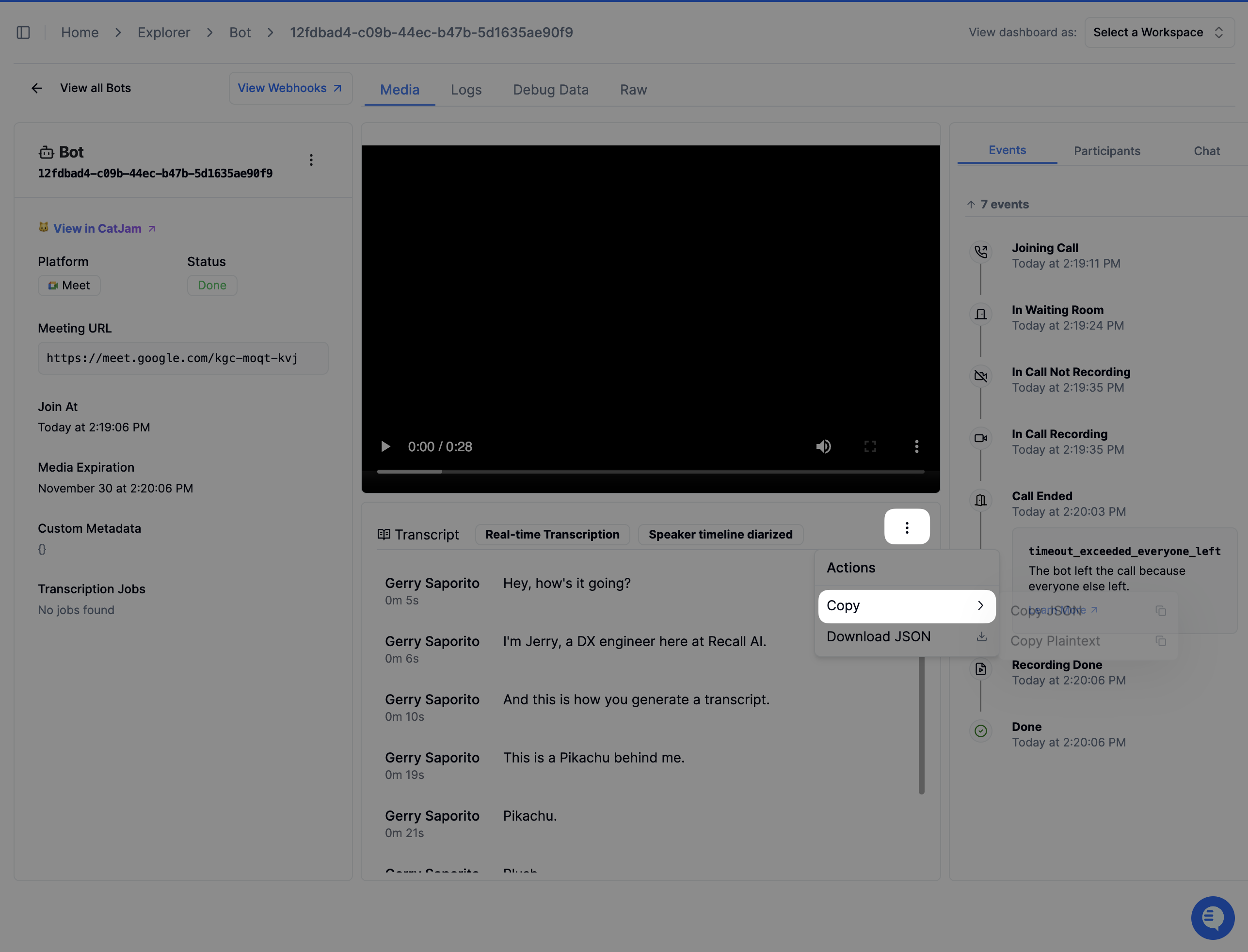
You can also programatically generate this transcript yourself by getting the dialogue transcript
Can I upload content recorded outside of Recall.ai to be transcribed?
Recall.ai can only transcribe recordings that were generated via bots or the Desktop Recording SDK. Currently, you cannot upload media recorded outside of these sources to be transcribed.
How to re-transcribe recordings?
For bots, you can use this script to re-transcribe recordings.
How can I use a transcription provider that isn't supported by Recall?
You can also bring your own transcription provider and transcribe the audio for a meeting. You can do this by:
- Getting the audio per participant from the meeting (async guide and real-time guide)
- Passing the audio to your AI transcription provider or run it through your own model
Will screenshare audio be transcribed?
Yes, screenshare audio can be transcribed when using transcription with separate streams enabled (diarization.use_separate_streams_when_available: true).
Updated 25 days ago